Security Questionnaires should be one of the easiest problems for AI to solve. A vendor sends you a spreadsheet of questions. You have a library of approved answers. Match question to answer, fill in the blanks, done.
That is how we pitched it internally 18 months ago. It took us about two weeks of building to realize how wrong that mental model was. This post is about the complexity we discovered, the approaches that failed, and the architecture we landed on after iterating through three major rewrites.
But before we jump into breaking down the problem further, let’s first understand what security questionnaires are and why vendors receive them.
What is a Security Questionnaire, and why does a vendor get one?
A security questionnaire is a structured document that one company sends to another to evaluate how that company handles information security, data privacy, and compliance. They're almost always part of a vendor risk management or third-party risk management (TPRM) process. The sender wants to understand the risk of doing business with the receiver.
These security questionnaires typically contain anywhere from a few dozen to several hundred questions covering areas like:
- Access controls and authentication (MFA, SSO, password policies)
- Data encryption
- Business continuity and disaster recovery
- Infrastructure and cloud security
For vendors receiving them, questionnaires are often a significant sales-cycle bottleneck, requiring time and manual effort to respond to questions and gather supporting evidence.
The format problem is worse than you think
Our first prototype assumed questionnaires arrive as clean spreadsheets. Column A is the question. Column B is where you type the answer. Ship it.
Then we looked at real customer data. One customer alone had received questionnaires in 47 distinct formats in a single quarter. Merged cells. Color-coded columns where the color carries semantic meaning. Nested PDF forms with radio buttons. Vendor portals with no export button. Word documents where questions are buried inside paragraph text with no clear delimiter.
The format diversity is not random. Every enterprise that sends a security questionnaire has its own compliance team, its own template, and its own opinions about how questions should be organized. Some follow SIG. Some follow CAIQ. Most follow nothing except whatever their legal team invented five years ago.
Our first parser handled about 60% of incoming formats. That sounds decent until you realize that 40% failure means 40% of your customers' questionnaires break. We rebuilt the parser three times before landing on a format-agnostic approach that treats every document as an unstructured input and extracts question-answer structure using the AI itself, not hardcoded rules.
The lesson: if your AI tool only works on clean inputs, it does not work. Security questionnaires are messy by nature, and the messiness is the product problem, not an edge case.

Why simple RAG fails for compliance answers
The obvious architecture for this problem is retrieval-augmented generation. Embed your policy documents. When a question comes in, retrieve the most relevant chunks. Generate an answer from those chunks. Standard pattern.
We built exactly that. It produced plausible-sounding answers about 70% of the time. The other 30% ranged from subtly wrong to dangerously incorrect.
The core issue is that compliance answers are not just "what does our policy say?" They are "what does our policy say, filtered through how we have answered this exact question before, verified against the evidence we have already collected, and phrased in the specific way our compliance team has approved."
A pure RAG approach misses the institutional knowledge layer. Your ISO 27001 policy might say one thing about access control. But the answer your compliance team gives to the question "Describe your access control procedures" includes specific tooling references, process details, and nuance that the policy document does not contain. That answer was refined over dozens of questionnaire submissions.
This is what led us to a four-tier answer hierarchy. The AI checks the curated Answer Library first (human-approved answers to known questions). If no match is found, it looks at published policies. Then, evidence in the Trust Vault. Then, prior questionnaire submissions. Each tier adds context, but the curated tier is the authority.

Building this hierarchy was harder than building the RAG system. The retrieval part is table stakes. The ranking, deduplication, conflict resolution, and confidence scoring across four sources is where the real engineering lives.
One question, five interpretations
Here is a question that appears on almost every security questionnaire: "Describe your encryption practices."
That single question could mean at least five different things. Are they asking about encryption at rest? In transit? For backups? For end-user devices? For your database layer specifically? The "correct" answer depends entirely on what the questioner actually wants to know, and they rarely specify.
Our first approach was to have the AI select the most likely interpretation and generate a single answer. That worked about half the time. The other half, the AI, would write a detailed response about TLS configurations when the questioner actually wanted to know about disk encryption on employee laptops. The answer was correct. It was the answer to a different question.
This taught us something important about AI-assisted compliance tools. When a question is ambiguous, the tool should not silently pick one interpretation. It should show you the options upfront. Here are three ways we can read this question. Here is what we would answer for each. You pick.
That design shift, from "the AI decides" to "the AI proposes, you decide," changed our accuracy metrics more than any model improvement we made. Ambiguous questions are not an edge case. They are roughly a third of most questionnaires. If your tool pretends every question has exactly one interpretation, it is guessing on a third of the answers and hoping you do not notice.
Giving users control over what the AI knows
Even after you resolve the interpretation, the question of where the answer comes from matters. Your Trust Vault might contain 200 documents. Not all of them are relevant to every questionnaire.
A healthcare customer asking about encryption practices needs answers grounded in your HIPAA-related evidence. A financial services customer needs your PCI DSS documentation. If the AI indiscriminately retrieves from the entire vault, it will pull the wrong context for the wrong audience.
We built a tagging system on the Trust Vault that lets users configure which data sources feed into the autofill for a given questionnaire. Tag your documents by framework, by customer segment, by topic. When you start a new questionnaire, select the relevant tags, and the AI only retrieves from that subset.
This prevents the system from pulling your SOC 2 evidence when the questionnaire is asking about GDPR. It gives the user explicit control over the knowledge boundary within which the AI operates. The AI does not decide what is relevant. You do.
The combination of surfacing interpretation options and scoping data sources by tags addressed our single biggest source of “technically correct but wrong” answers. The AI still does the heavy lifting. But the human stays in the loop on the two decisions that matter most: what does this question mean, and what evidence should inform the answer.

The attachment problem nobody talks about
Here is something we did not anticipate at all. A significant portion of security questionnaire fields do not ask for text answers. They ask for file attachments. "Please attach your SOC 2 report." "Upload your incident response plan." "Provide your network diagram."
Most AI-powered questionnaire tools ignore this entirely. They generate text for text fields and leave attachment fields blank. The user still has to manually hunt for the right document in their Trust Vault, download it, and attach it. For a questionnaire with 30 attachment requests, that manual step alone takes hours.
We built Teammates to recognize when a question requires a document rather than a text answer, identify the correct document from the Trust Vault, and automatically attach it. This sounds straightforward in a blog post.
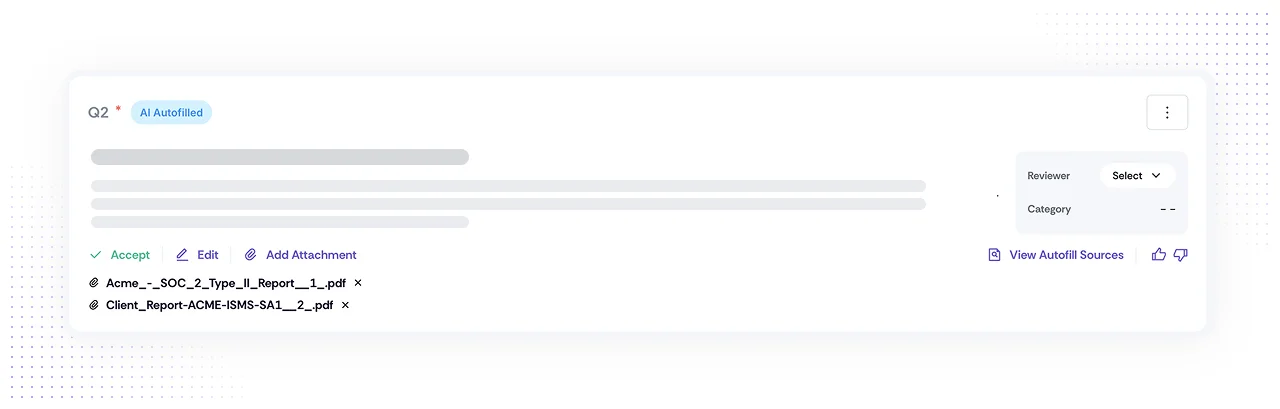
In practice, it required teaching the AI to understand the difference between "describe your incident response process" (text answer) and "provide your incident response plan" (document attachment), and then resolving which of the 15 documents in your Trust Vault tagged "incident response" is the one this specific question is asking for.
The compounding context advantage we did not design for
Something unexpected happened once customers started using the autofill at volume. The system improved with each questionnaire, not because we retrained the model.
Every time a user accepts an AI-generated answer (or edits it and then accepts it), that answer is added to the library as a verified response. The next time a similar question arises, the AI will have a higher-confidence source to draw from. Over time, the Answer Library becomes a living, curated knowledge base of exactly how your organization answers security questions.
We did not design this as a feature. We designed the Answer Library as a static reference. The compounding effect emerged from the workflow, where completing questionnaires naturally generates training data for future questionnaires. Now, it is one of the system's strongest parts.
The lesson here is that the best data flywheels are the ones your users create without trying. If completing the task also improves the tool, adoption reinforces itself.
What we still get wrong
Transparency matters here. This system is not perfect, and we do not pretend it is.
Vendor portals with dynamically rendered JavaScript forms remain difficult. Our browser extension handles most portal-based questionnaires, but some portals fight back with aggressive anti-automation measures. We handle this by falling back to manual mode, but it is a real limitation.
And confidence calibration is an ongoing challenge. When the AI says it is 85% confident in an answer, is that actually 85%? Calibrating confidence scores so they mean what they claim to mean is a separate research problem that we are investing in through our eval framework.
The bottom line
Security questionnaire autofill looks like a straightforward AI problem from the outside. Match the questions to the answers, and fill in the blanks.
In practice, it requires solving format parsing across thousands of templates, building a multi-source answer hierarchy that respects institutional knowledge, handling the ambiguity inherent in how questions are phrased, giving users control over which sources the AI draws from, and automating document attachment with semantic understanding.
We are still learning. Every batch of questionnaires surfaces new edge cases, new formats, and new ways that the AI can be confidently wrong. The difference now is that we have the architecture to catch those failures and feed them back into the system.

.png)





.png)