A deal slows down. A security questionnaire is pending. An auditor asks for evidence that is not readily available. Your team knows the controls exist, access is managed, logging is in place, and policies are defined. But when proof is required, it takes time to assemble, verify, and present it in the format expected. Engineering gets pulled in to export logs and validate configurations. Compliance teams chase down screenshots and fill gaps across systems.
What should be a straightforward validation exercise turns into a time-bound effort that disrupts ongoing work and delays outcomes that depend on it.
The reason is that controls are rarely missing. It is where compliance work actually lives, scattered across Jira tickets, Slack threads, manual spreadsheet entries, and Google Drive folders. This disconnect sharpens as organizations scale.
A team expanding across geographies or adding frameworks like ISO 27001 alongside SOC 2 is not just doing more compliance work; it is managing more systems, more stakeholders, and overlapping audit cycles simultaneously. What worked when one person could hold context in their head breaks down when that context is distributed across a growing team and multiple tools, with no single source of truth.
This is where GRC solutions make a difference, and specifically where a compliance automation platform earns its place. Instead of chasing evidence at audit time, a modern GRC solution connects to the systems where work already happens, continuously captures proof, and keeps it mapped to the right frameworks; so when an auditor or customer asks, the answer is already there.
Why GRC feels broken in practice when organizations start scaling
GRC is expected to operate continuously. In practice, it is still managed in cycles. This is where the friction begins.
The issue is not that controls are missing. It is that the way GRC is executed does not match how modern systems operate.
This shows up in very real ways.
- You do not have real-time visibility into whether controls are working
Controls are checked at specific points in time. That creates a gap between what the system looked like during the last review and what it looks like now. Between those checks, you are relying on assumptions. If access changed last week, a screenshot from last quarter does not help much. When an auditor asks for proof, you are validating the past, not the present. At scale, stale evidence becomes a structural problem, not an administrative one.
- Evidence collection turns into a recurring time drain
A mature program may need to satisfy SOC 2, ISO 27001, customer questionnaires, internal reviews, and board-level reporting. The underlying controls often overlap, but the work does not. Each audit cycle, teams pull the same logs, export the same configurations, and recreate the same documentation. What should be reusable work gets repeated across frameworks and audits.
- Engineering gets pulled into compliance work
Engineering should own the system configuration, not the mechanics of audit assembly. Yet, your staff engineer spends 2–3 days pulling AWS logs, validating access settings, and explaining configurations instead of shipping features. When this becomes a pattern, not a one-off request, the shipping capacity starts taking a hit because your engineers are too busy with compliance busywork rather than working on product deliverables.
- Evidence lives across systems, tickets, and tribal knowledge
The proof you need is rarely stored in one place. Some of it lives in identity systems, cloud platforms, repositories, ticketing tools, HR workflows, and policy documents. Some of it lives in someone’s head. When evidence is distributed this way, compliance becomes a retrieval problem before it becomes a governance problem.
- Ownership breaks where control work crosses teams
GRC owns framework requirements. Engineering owns systems. IT owns identity and endpoint controls. Security owns monitoring and exceptions. Each team owns part of building the audit proof, but no one owns the full path from the control requirement to the current evidence. That is where delays, inconsistencies, and remediation drift tend to appear.
- Audits start disrupting core business timelines
Many teams still enter a high-effort mode before audits: evidence requests go out, gaps are discovered late, and remediation gets prioritized under deadline pressure. Product work slows down. Sales waits for responses. Internal teams shift focus from building to proving. That is a sign that your audit readiness is event-driven rather than built into the way the control environment is run.
Over time, this compounds.
You spend significant time year over year on repetitive audit tasks. On average, 54% of security teams spend five or more hours each week on manual compliance tasks. The workload does not reduce. It simply gets redistributed across more systems, more frameworks, and more stakeholders.
How GRC actually works when organizations start scaling: From controls to decisions
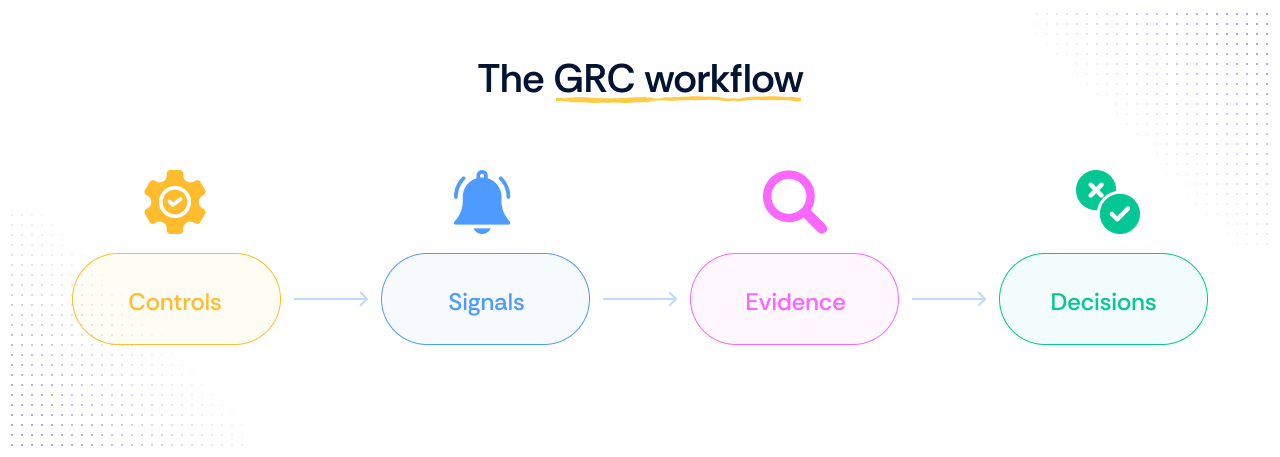
If you have been working in the GRC space for some time, you already know that for any GRC program to function efficiently, this is one of the most effective operational flows:
Controls → Signals → Evidence → Decisions
- Controls define what should happen.
- Signals show what is actually happening.
- Evidence turns those signals into something auditors can act on.
- Decisions follow.
What is worth examining is what happens to this flow when your organization stops being a single, stable environment and starts becoming something more complex.
Where the flow starts to fracture
When your scope was one entity and one framework, the flow held together. Then something changed:
- A new entity was added, or an acquisition brought in different infrastructure
- A customer required ISO 27001 on top of your existing SOC 2
- A new market introduced new regulatory obligations
- The team grew, and informal ownership of controls no longer held
Each of these events does not just add work. It breaks the assumptions on which the flow was built.
The control still exists. But:
- The signal source is now different across entities
- The evidence format that satisfied one framework does not satisfy another
- The person who owned that control in the original entity does not own it in the new one
- Nothing was designed to be portable, so your team rebuilds from scratch each time
This is the compliance scaling problem in practice. Not a gap in controls. A flow that was never built to absorb change.
What actually sustains the flow at scale
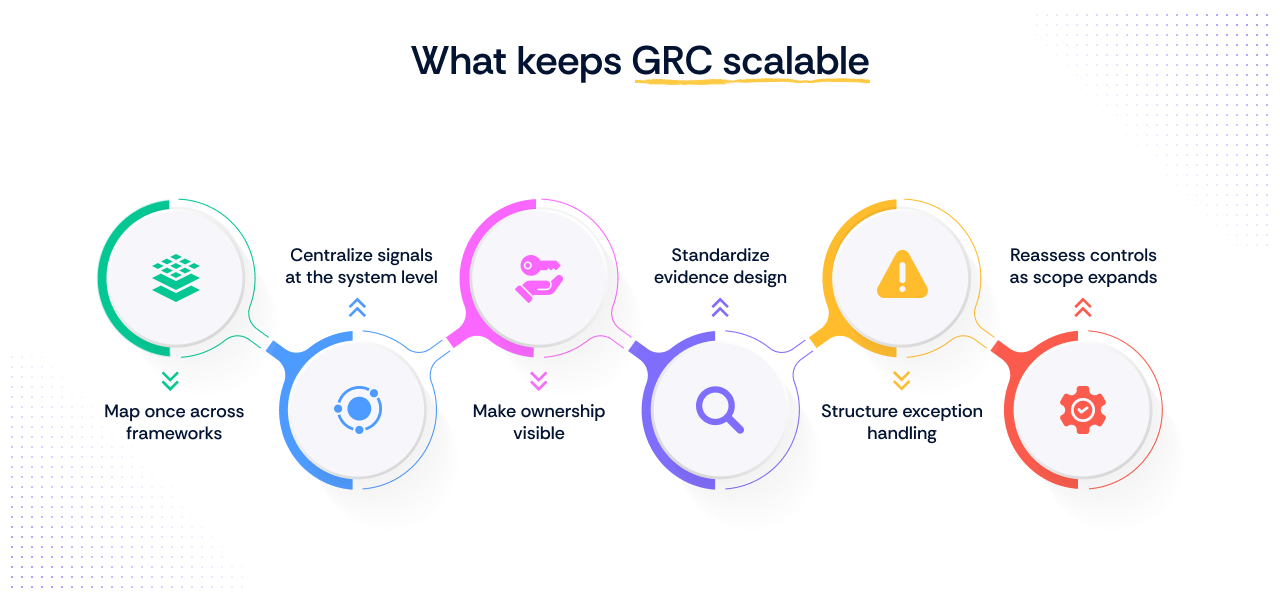
For GRC heads managing multiple entities, frameworks, or geographies, three structural decisions determine whether the flow holds or fractures with each new addition.
1. Map controls once, not per framework
When a control like MFA enforcement is mapped across SOC 2, ISO 27001, and other applicable frameworks from the start:
- Evidence collected for one audit becomes reusable for the next
- Control gaps surface once, not repeatedly across separate workstreams
- New framework additions become a mapping exercise, not a rebuild
Without this, every new framework runs as a parallel effort alongside everything else.
2. Centralize signal collection at the system level, not per entity
A new subsidiary joining the environment should plug into an existing evidence pipeline, not require a new one. Ask:
- Are the systems in this new entity generating the right signals?
- Can those signals feed into the same evidence pipeline that already exists?
- Or will this entity require a separate, manual evidence collection process?
If signals are being pulled manually per entity per audit, the effort multiplies with every addition rather than staying constant.
3. Make ownership explicit, not assumed
At smaller scale, one person can hold context informally. At a larger scale, that is where evidence gaps appear and remediation stalls. For each control, define:
- Who owns it
- Which system generates the signal
- What the evidence path looks like
- Who is responsible when the scope changes
When this structure exists, adding a new entity or framework is an extension of what already works, not a rebuild of the entire flow.
When these three things are in place, growth does not break the flow. It extends it.
4. Standardize evidence design early
A control can be mapped correctly and still create friction if the evidence behind it is inconsistent. One team uploads screenshots, another links tickets, and a third exports logs with no clear context. That may work at small scale. It does not hold when multiple teams, entities, or audits rely on the same control.
Define early what acceptable evidence looks like for each control, where it comes from, how current it needs to be, and how it should be stored. Without that consistency, the flow slows down at the point where evidence needs to be reviewed, reused, or defended.
5. Build exception handling into the model
Not every control will operate in a clean, standard way across every team or entity. A temporary deviation, a delayed remediation, or a compensating control does not just create a governance issue. It creates flow friction if there is no structured way to record, approve, and track it.
At scale, exceptions cannot live in side conversations or isolated spreadsheets. They need a defined path, with clear ownership, review timelines, and supporting rationale. Otherwise, the control may exist, but the evidence trail around it does not hold up when scrutiny increases.
6. Tie scope changes back to control design
A new business unit, tool, geography, or acquisition does not just expand the environment. It changes the shape of the control system itself. The signal source may shift. The owner may change. The evidence path may no longer hold in the same way.
If scope changes are treated as simple administrative updates, the flow starts to drift before anyone notices. At scale, each scope change should trigger a review of control applicability, signal coverage, and ownership so the operating model stays intact as the environment evolves.
Transitioning to modern GRC solutions
Traditional approaches to GRC were designed around audits. Teams prepared at fixed intervals, gathered evidence manually, and validated controls at a point-in-time. That model worked when systems were simpler and audits were less frequent.
As systems became more dynamic, this approach started to fall behind. The shift to modern GRC is not about adding more controls. It is about changing how GRC operates. Modern GRC solutions are built around three core capabilities that traditional approaches simply were not designed for:
- From point-in-time validation to continuous monitoring
Controls are no longer checked once every few months. They are monitored continuously, so you always know whether they are working as expected.
- From manual evidence collection to system-generated evidence
Instead of pulling screenshots and exporting logs during audits, evidence is created automatically from system activity and kept up to date.
- From audit-driven workflows to risk-driven decisions
The focus moves from preparing for the next audit to understanding what is happening in your systems right now and responding to risks as they emerge.
This shift aligns GRC with how modern systems operate. It reduces the gap between system activity and compliance validation and removes the need for reactive, last-minute effort.
How to scale GRC without derailing engineering
Scaling GRC usually fails for one reason. The work grows faster than the system handling it.
As you add frameworks/standards, audits, and customers, the volume of proof increases. If that proof is still assembled manually, the effort compounds. Teams spend more time coordinating evidence than managing risk.
Scaling GRC is not about adding more controls. It is about reducing the effort required to prove the controls you already have.
To do that, you need clarity on three questions:
- What gets automated?
- What stays manual?
- Who owns what?
Let’s break down each to understand.
What to automate vs what stays manual
Not every part of GRC is (or should be) automatable. The goal is to automate what is repeatable and system-driven, and keep human involvement where judgment is required.
AI is accelerating this significantly, from mapping controls across frameworks to flagging deviations and keeping evidence current; tasks that once took days can now run continuously in the background. But the final call always stays with the human. Accepting a risk, approving an exception, or deciding how a deviation impacts the business are decisions that require context and accountability that no system can substitute.
1. Automate what your systems already know:
- Identity and access data, such as user provisioning and MFA enforcement: Access events are logged continuously. Automating this means you always have current proof of who has access to what, without chasing it down before every audit.
- Cloud configurations, including logging, encryption, and network controls: Cloud platforms record every configuration change in real time. Automating evidence collection here eliminates the need for manual exports and point-in-time screenshots.
- Repository activity, such as access changes and code merges: Code repositories track every action. This data maps directly to controls around change management and access governance.
- Continuous control monitoring and evidence generation: Rather than validating controls at a fixed point in time, automation keeps evidence current and flags deviations as they occur.
These areas already produce signals. Modern GRC solutions focus on converting those signals into usable evidence without requiring repeated effort.
2. Keep it manual where context matters:
- Policy creation and updates: Policies need to reflect how your organization actually operates. They require input from legal, alignment with executive leadership, and sign-off from stakeholders who understand the business implications. No system can substitute for that process.
- Risk acceptance and exception handling: Deciding whether a risk is acceptable involves weighing business priorities, timelines, and constraints that exist outside any system. These decisions need a named owner and a documented rationale.
- Context-driven reviews and approvals: Periodic reviews of access, vendor relationships, and control effectiveness require human judgment about whether what the system shows reflects acceptable real-world behavior.
Automation handles consistency. Humans make decisions.
3. What needs a human in the loop
Even with the best automation in place, GRC is not fully automated. Certain areas require context, judgment, and accountability that systems alone cannot provide.
Human involvement is critical in:
- Defining and evolving controls: Deciding what matters for your business, how strict a control should be, and how it aligns with risk appetite requires someone who understands both the regulatory requirement and the operational reality of your environment.
- Evaluating exceptions and trade-offs: Not every deviation is a failure. Some risks are accepted based on business priorities, timelines, or constraints. That determination requires a person with the authority and context to make it.
- Interpreting signals in context: A failed control or unusual activity needs investigation. Systems can flag it, but understanding whether it reflects a genuine gap, a known exception, or a configuration quirk requires human judgment.
- Driving remediation and cross-team coordination: Fixing issues often requires collaboration across engineering, security, and IT. Systems can surface the problem and track progress, but the coordination itself cannot be automated end-to-end.
- Communicating with auditors and stakeholders: Evidence may be system-generated, but explaining intent, scope, and the decisions behind your control design still requires human clarity and accountability.
This is the balance modern GRC solutions aim for. Systems handle scale and consistency, while humans focus on judgment and decision-making.
Ownership model (who owns what)
One of the most common reasons GRC breaks at scale is unclear ownership. Work gets distributed across teams, but accountability for evidence is not clearly defined. When no one owns the full path from control requirement to current evidence, gaps appear and remediation stalls.
A RACI model brings clarity to this. For each compliance activity, one team is Responsible for doing the work, one is Accountable for the outcome, others are Consulted for input, and the rest are simply Informed.
Here is how this maps in practice:
Implementation Timeline: 30/60/90 day shift to move from reactive to continuous GRC
A common concern at this stage is time. How long will it take to move away from manual, audit-driven compliance, and will it disrupt ongoing work? In practice, this transition is incremental and outcome-driven. You are not ripping out existing processes overnight. You are systematically replacing manual effort with system-driven evidence, one layer at a time.
Day 0–30: establish visibility
You move from guessing to knowing where your evidence lives.
- Connect core systems such as cloud, identity, and repositories
- Map key controls to system signals
- Begin automated evidence collection for high-impact controls
Day 30–60: reduce manual effort
You stop recreating evidence for every audit.
- Replace spreadsheet-based tracking with system-driven evidence
- Identify gaps and noisy controls
- Reduce repeated audit preparation work
Day 60–90: move to continuous readiness
Audits stop disrupting engineering workflows.
- Enable continuous monitoring of controls
- Run internal audit simulations
- Minimize engineering involvement in evidence collection
Teams that adopt this model typically reduce audit preparation from weeks to days and significantly reduce engineering time spent on compliance tasks.
What actually improves (and what does not)
A common concern is whether this reduces work or simply reorganizes it.
In practice, the change is visible in a few areas:
- Audit preparation becomes predictable instead of reactive
- Security questionnaires are completed faster because evidence is readily available
- Engineering is no longer pulled into repeated evidence requests
What does not change is the need for oversight. Policies still need to be defined, and exceptions still require review. GRC does not become zero-effort; it becomes structured and system-driven rather than repetitive.
What good GRC looks like in practice
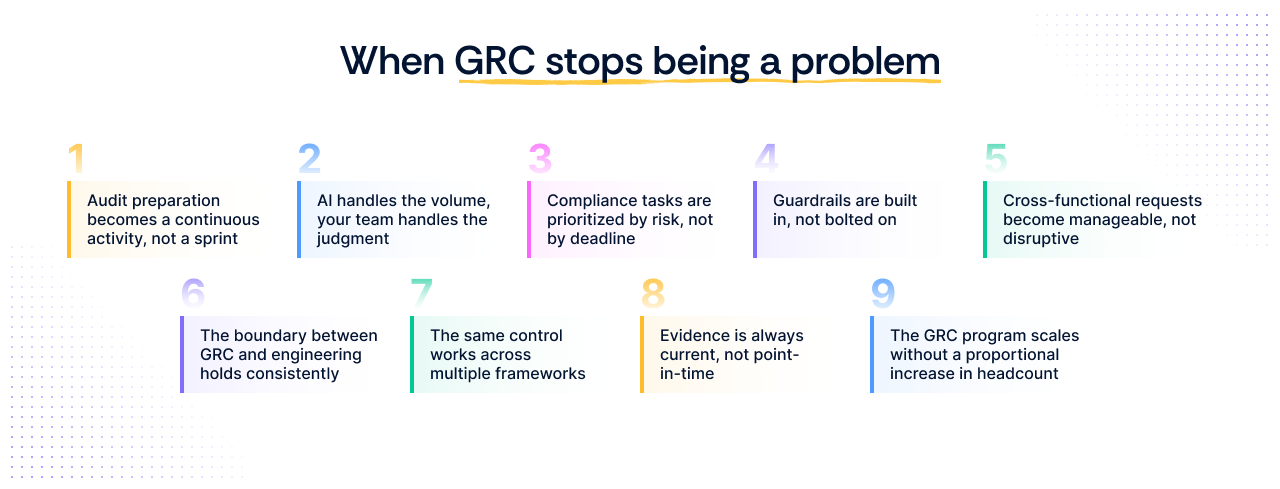
At this stage, the question is no longer what GRC is or how it works. It is what changes once it is set up correctly.
Good GRC does not equate to better documentation. It shows up in how work flows across teams, how quickly your program responds to change, and how much of the heavy lifting happens without anyone having to ask for it.
1. Audit preparation becomes a continuous activity, not a sprint
There is no longer a defined period where everything stops so evidence can be assembled. Controls are monitored continuously, evidence is always current, and when an audit begins, your team is validating rather than scrambling. When an auditor asks for something outside the standard request list, the answer is already there.
2. AI handles the volume, your team handles the judgment
Modern GRC programs are beginning to use AI to do what no team has the bandwidth to do manually: monitor controls continuously across every system, surface deviations as they happen, suggest remediation paths, and flag evidence that is stale or incomplete before it becomes an audit finding. This does not replace the GRC function. It frees it up to focus on decisions that actually require expertise rather than on evidence retrieval and status tracking.
3. Compliance tasks are prioritized by risk, not by deadline
In a reactive GRC program, what gets attention is whatever the next audit requires. In a well-structured one, risk drives prioritization. High-impact controls with active deviations get addressed first. Low-risk, stable controls are monitored in the background. Your team's time goes where it actually matters, not where the calendar says it should.
4. Guardrails are built in, not bolted on:
Good GRC does not rely on people remembering to follow the process. Guardrails are embedded into workflows so that when a new system is onboarded, it is automatically assessed against existing controls. When access is provisioned, it is logged and mapped. When a configuration changes, it is flagged against the relevant control. The program runs continuously rather than being activated at audit time.
5. Cross-functional requests become manageable, not disruptive
Security questionnaires and customer requests are handled quickly because evidence is well-structured, up to date, and easy to access. For a GRC manager, this also means fewer ad hoc requests landing from sales, legal, or customers at inconvenient times, and less time spent translating compliance status into a language that different stakeholders can understand.
6. The boundary between GRC and engineering holds consistently
Engineering teams focus on building and maintaining systems, not exporting logs or explaining configurations during audits. For a GRC manager, this matters beyond efficiency. When engineering is repeatedly pulled into compliance work, it creates friction that makes future collaboration harder. A well-structured program protects that boundary so that when you do need engineering involvement, it is for the right reasons.
7. The same control works across multiple frameworks
Instead of recreating evidence for SOC 2, ISO 27001, and others, controls are mapped once and reused. For a GRC manager overseeing multiple frameworks or preparing for a new certification, this means the groundwork you have already laid does not need to be rebuilt. It just needs to be extended.
8. Evidence is always current, not point-in-time
You are not relying on snapshots taken during audits. Evidence reflects actual system behavior continuously. This also means that when a control fails, you know about it immediately rather than discovering it when an auditor does.
9. The GRC program scales without a proportional increase in headcount
As frameworks are added, entities grow, and audit cycles overlap, the volume of compliance work increases. In a manual program, that volume requires more people. In a system-driven one, the program absorbs growth because evidence collection, control monitoring, and framework mapping are handled systematically. Your team grows in scope without necessarily growing in size.
Where GRC solutions fit in
Up to this point, the focus has been on how GRC should operate as a system. Not tools, not features, but the underlying model that connects controls, signals, and evidence.
This distinction matters because tools alone do not fix broken GRC. If the process is still manual and fragmented, software only ends up organizing the same inefficiencies in a better interface. The role of GRC solutions becomes clear only when you understand what they replace and what they make possible.
Here is how the three common approaches compare:
How Scrut helps you get and stay continuously compliant
Scrut connects directly to your core systems, continuously captures signals, maps them to controls, and converts them into structured, audit-ready evidence so proof is always available without anyone having to go looking for it. Controls are mapped once and reused across frameworks, ownership is defined in one place, and real-time reminders ensure nothing falls through the cracks between audit cycles.
Scrut Teammates, a system of vertical AI agents built specifically for GRC, handles the grunt work your team should not have to do. It prioritizes failed controls based on audit context and risk severity, auto-fills security questionnaires from your existing policies and answer library, flags stale or incomplete evidence before it becomes an audit finding, manages vendor risk assessment end-to-end, and creates and assigns tickets to the right owners without anyone having to chase. Your team stays in control throughout. Every action Teammates takes is visible, reviewable, and requires human sign-off where it matters.
Take a guided demo and see how Scrut fits into your stack, how quickly you can move to continuous readiness, and what it takes to reduce the manual load on your team.
Because the work shifts from implementing controls to repeatedly proving them. As tools, frameworks, customers, and audits increase, manual evidence collection grows faster than the team tasked with handling it.
They are periodic, while your systems are continuous. You end up validating snapshots during audits instead of knowing what’s happening in real time, which creates gaps and last-minute work.
They automate the flow from signals to evidence. Instead of pulling logs and screenshots each time, your systems continuously generate audit-ready proof mapped to controls.
No, it shifts the role. GRC tools handle repetitive tasks, such as evidence collection, while humans focus on decisions such as risk acceptance, exceptions, and control design.
You’ll see recurring signs: -Engineers are spending more time collecting evidence than shipping -Repeating the same work across different audits -Deals stalling due to slow or inconsistent responses to security questionnaires -Lack of real-time visibility and monitoring of controls -These indicate the system is not scaling with your business